Ein Gastbeitrag von Christian „Schepp“ Schaefer
Dieser Artikel dreht sich um ein immer populärer werdendes Thema, nämlich um die Frage, wie man die Ladezeiten von Webseiten reduzieren kann. In diesem Kontext schauen wir uns mit Fokus auf das Frontend zunächst an, welche Verursacher es geben kann, die unsere Seite langsam werden lassen, und welche Techniken es gibt, um gegen sie anzuarbeiten. Im unteren Drittel stelle ich Euch dann eine PHP-Bibliothek namens „CSS-JS-Booster“ vor, die Ihr ganz einfach in Euer PHP-Projekt einbinden könnt, und die Euch die wichtigsten Optimierungsschritte abnimmt (vor allem rund um CSS und JS). Und wir reden kurz über ein auf die Bibliothek aufsetzendes Wordpress-Plugin.
Die Ladezeit ist ein Erfolgsfaktor
Seit Samstag ist es offiziell: Auch die Ladezeit einer Seite wird künftig zu einem von rund 200 Faktoren zur Bestimmung des Rankings innerhalb der Google-Suchergebnisse. So verkündeten es Amit Singhal und Matt Cutts im Webmaster Central Blog.
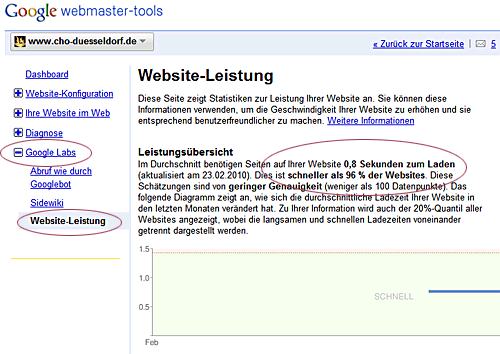
Wer Googles Aktivitäten in den letzten Monaten etwas detaillierter verfolgt, für den fällt das nicht aus so ganz heiterem Himmel. Der googlesche Geschwindigkeitswahn nahm Ende 2008 mit dem Release der ersten Chrome Beta, der einige neue Tricks kannte, Fahrt auf. Weiter ging es Mitte 2009 mit dem Firebug-Plugin Google Page Speed, dann der Speed Tracer und Ende 2009 mit dem Google Public DNS, der DNS-Resolving mit einigen Tricks deutlich schneller bewerkstelligt, und ebenfalls seit Ende 2009 gibt es in den Google Webmaster Tools in der Sektion „Labs“ einen Bereich der über die Ladegeschwindkeit der eigenen Seite - auch im Vergleich zum Rest der Welt - informiert.
Eine schnelle Seite ist angenehm zu bedienen
Warum all das? Nun, Google möchte einfach ein so gutes und schnell ansprechendes Web haben, dass es den Einsatz von Offline-Applikationen überflüssig macht. Das stärkt die Position von Android und von Googles zukünftigem Desktop-OS Chrome OS.
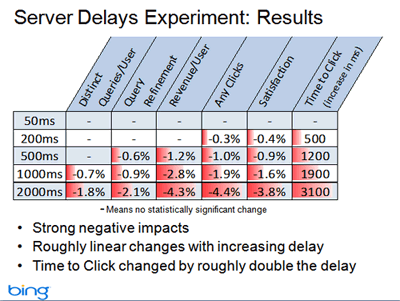
Aber es macht natürlich ganz allgemein mehr Böcke auf einer Seite herumzusurfen, die schnell lädt und die auf Eingaben zügig reagiert. Es handelt sich also um einen handfesten Usability-Aspekt. Und es bestimmt auch maßgeblich die Konversionsrate mit, so man denn bestimmte messbare Ziele mit seiner Seite verfolgt.
Google ist nicht der erste größere Webtechnologie-Konzern, der sich in diesem Sektor engagiert: Schon 2007 gründete man bei Yahoo! ein Team, das sich nur mit Performance-Fragen beschäftigte: das „Yahoo! Exceptional Performance Team“ unter der Leitung des „Chief Performance Yahoo!“ namens Steve Souders (BTW: Coole Jobbezeichnungen, oder?).
Und ebenjener Steve Souders, der heute übrigens für Google tätig ist, schrieb damals ein relativ dünnes Buch namens „High Performance Websites“, über das ich im Folgenden in einer Buchhandlung stolperte. Das Ding ist zwar mäßig gut übersetzt, aber nichtsdestotrotz Gold wert (und mittlerweile flankiert von seinem anderen Buch „Even faster Websites“).
Was macht unsere Seiten schnell?
In „High Performance Websites“ beginnt Souders mit der Feststellung, dass wir mehr gefühlte Performance für weniger Arbeit erhalten, wenn wir uns auf die Optimierung unseres Frontends konzentrieren, als wenn wir am Backend herumschraubten. Im Anschluss benennt er 14 „goldene“ Regeln, die im Bereich der Frontend-Entwicklung entscheidend für die Ladezeiten einer Website sind, und sortiert sie nach Priorität. Je weiter oben eine Regel steht, umso wirkungsvoller ist sie:
- Anzahl HTTP-Requests (= Datei-Requests) minimieren
- Ein Content Delivery Network verwenden
- Dateien mit längeren Verfallsdaten ausstatten
- Daten komprimiert verschicken
- Stylesheets in den Quelltext-Kopfbereich
- JavaScripts in den Quelltext-Fußbereich
- Keine Internet Explorer Expressions in Stylesheets verwenden
- Stylesheets und JavaScripts nicht einbetten, sondern in Dateien auslagern
- Maßvoll viele DNS-Anfragen erzeugen
- JavaScript minifizieren (CSS aber auch)
- Umleitungen vermeiden
- Doppelungen/Redundanzen bei den JavaScripts vermeiden
- Auf dem Webserver die ETag-Header abschalten
- AJAX-Anfragen cachen
Zusammen mit dem Buch hat Yahoo! damals die Firebug-Erweiterung YSlow! released, die eine Webseite auf das Erfülltsein der Punkte dieser Liste hin untersucht. Am Ende gibt es soundsoviel von 100 Punkten und eine Performance-Klassifizierung von A (für top!) bis F (für schnarchlahm).
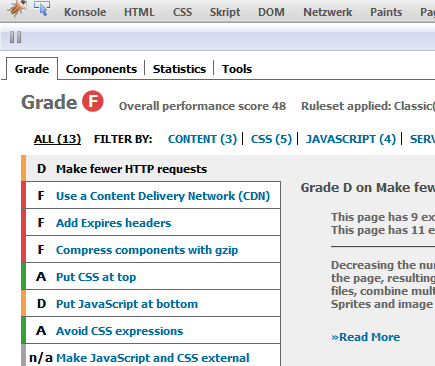
Die Einstellung mit den 14 Regeln heißt „Classic V1“. Später kamen weitere 8 Regeln hinzu (Setting: „YSlow(V2)“), die größtenteils auf die Darstellungsperformance innerhalb der Renderengine während der Benutzung abzielen. Da kommen aber nicht ganz so Gravierende hinzu weswegen ich weiter über das „Classic“-Set reden werde.
In der obigen Liste gibt es Punkte, die eher für Enterprise-Seiten wichtig sind, als für Ottonormal-Seiten, weswegen YSlow! neben „YSlow(V2)“ auch einen milderen Bewertungspreset namens „Small Site or Blog“ für uns vorhält, der diese Punkte ausklammert. Mit der Zusammenstellung gehe ich aber nicht 100pro konform (die Sache mit dem Verfallsdatum fehlt da zum Beispiel!).
Einige der Regeln habe ich in fett hervorgehoben, weil sie die für uns Webworker interessantesten Regeln sind. Die schauen wir uns im Folgenden nochmal genauer an.
Anzahl HTTP-Requests (= Datei-Requests) minimieren
Im Gegensatz zu früher, als es noch kein breitbandiges Internet gab, bestimmt das Gewicht einer Seite (also die Bytes) die Ladedauer immer weniger. Mit steigendem Durchsatz merkt man den Transfer von sagen wir mal 1 Megabyte kaum: bei DSL 6000 dauert der etwa 1,7 Sekunden. Bei VDSL-25 sind es nur noch 0,4 Sekunden. Das Problem heute ist die Latenz, also die Zeit, die, egal wie dick eine Leitung ist, immer verstreicht bis der Datentransfer endlich losgeht. Und diese Latenz setzt sich aus 3 Teilaspekten zusammen:
- Falls es sich um einen unbekannten Host handelt: DNS-Anfrage
- Reisezeit der „Haben wollen“-Anfrage an den Server
- Reisezeit der „Da hast Du“-Rückantwort an den Browser
Erst danach kommt die Nutzlast. Je mehr Dateien wir also anfragen, desto mehr Latenzzeit läppert sich zusammen. Und je weiter der Server von uns weg steht, desto länger werden die Reisezeiten unserer Datenpakete.
Browser sind aber auch nicht blöd, nicht einmal der IE, weswegen sie hingehen und mehrere Anfragen parallel abfeuern. Obwohl HTTP 1.1 eigentlich nur zwei parallele Anfragen erlaubt, ignorieren moderne Browser diese Vorgabe und kommen auf 4 bis 6 parallelen Anfragen pro Host. Dadurch parallelisieren sich auch die Latenzen: sie liegen weniger zahlreich in Reihe und potenzieren sich somit weniger.
Leider hilft auch das nicht ganz aus der Bredouille, denn heutige Webseitenkonstrukte sind dermaßen angereichert mit Grafiken, JavaScript und anderen Komponenten, dass dieser Trick doch nur ein Tropfen auf einen recht heißen Stein darstellt. Beispiel: Allein dieses recht unkomplizierte Blog hier, benötigt 47 verschiedene Komponenten, um eine Seite vollständig anzuzeigen.
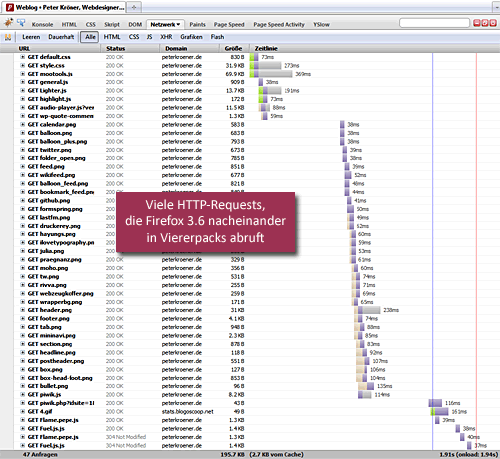
Die Devise lautet also: runter mit der Zahl der HTTP-Requests!
Wie machen wir das? Naja, je nachdem um was für Typen von Dateien es sich handelt, fügen wir sie entweder alle zu einer großen Datei zusammen: Bei JavaScript reicht wirklich das Hintereinanderhängen aller Scripte in der korrekten Reihenfolge. Bei Stylesheets sollten wir alle @import-Rules auflösen und wir sollten auch mehrere Stylesheets für verschiedene Ausgabemedien (Screen, Print, Mobile) per @media-Rule in eine einzige Datei integrieren. Im Falle von Bildern, aus denen Designelemente erzeugt werden können wir diese per Sprites, zusammenfügen, oder noch besser: per Data URI direkt als Nutzdaten in das CSS einbetten. In allen Fällen reduzieren wir im Idealfall die Anzahl benötigter Dateien auf eine Datei pro Datei-Typ (1 × CSS, 1 × JS, 1 × Bildsprite). Nehmen wir Data URIs brauchen wir sogar nicht mal mehr eine Bild-Datei.
Im Gegensatz zu den klassischen Sprites erlauben Data URIs das Vermengen von verschiedenen Bildformaten (z.B. JPG, 8-Bit- und 24-Bit-PNG) in einer Trägerdatei, sie erfordern weit weniger Gehirnakrobatik bei der Anwendung, und sie müssen bei Grafikänderungen nicht reihum neuorganisiert werden. Sie sind also praktischer. Aber vom Datenvolumen rund 30% größer als die Originale. Aber dafür gibt es auch Abhilfe, nämlich GZIP (siehe unten), und wie oben erwähnt ist das Datenvolumen nicht mehr unser Hauptproblem. So sehen Data URIs aus:
Vorher:
background: url(../design/quoted.gif) no-repeat left top;Nachher:
background: url(data:image/gif;base64,R0lGODlhEgAPANU/AGhSKtW7ZbOLOvbbXnplM
v7jabaXOZd7L+e/XUk6Hcu0bfTbZbWJRpB1LvXcgsSlUtSzQ4RpObueTCkiFMKWPeLDcjMsGd3G
V9qkUbunTty0WsOlPgcGAxcTDMaZO+TLXyMeDsqaSl5MKFRFJfLRetShTPvhhMWeN9/GY82dQcK
kSuK3Xue8YJdyQOzEXo9yL4RyOqyBR62SSq+SOM6tQSAbEdjBc8WYQODHY9CvV+jPWu/WXcioP8
uiOMqsSwAAACH5BAEAAD8ALAAAAAASAA8AAAavwJ9wSCwWJ4eLZDLkiAyfCFPYofQGropFKPJAC
ixb7ddhpAwZDSnAmYQ8aI0J9ktgbhZOrYJLtEoCIBwADio/IhgCHEIKKCIxJS9CEw4+dRgUCRMW
FSgWEYAJFgQOEj8cZic6CGscHW80CysmBFQCJzsIAVs/IxQQsgpjVAcDOR1NExsFEchNLwMPi03
LI0UcDdHTQhzLItfZ0kTdBd/jxeJNPOXXBBcy26czH9ZCQQA7) no-repeat left top;Beim Umwandeln der Dateien in Data-URI helfen uns Online-Tools wie das von Dopiaza.org oder aber wir basteln uns das mit PHP selbst:
echo 'background-image: url(data:image/gif;base64,'.base64_encode(file_get_contents('beispiel.gif')).');';Dummerweise vertragen die älteren IEs (sprich: IE < 8) Data-URIs nicht (IE 8 übrigens auch nur bis 24KB Größe pro Einzeldatei). Wir brauchen da also eine Sonderbehandlung im Stylesheet. Was die alten IEs an Standards nicht unterstützen, das machen sie an proprietären Techniken wieder wett, und so gibt es stattdessen MHTML für die älteren IEs. Dabei werden die Bilddaten nur aus dem Trägermedium heraus referenziert auf eine .mhtml-Datei.
Dummerweise fällt auch hier ein IE raus: der IE7 unter Vista. Unter Vista scheint ein neues Sicherheitsmodell zu verhindern dass MHTML wie zuvor funktioniert. Der Effekt ist der dass Bilder beim ersten Laden da sind, beim zweiten Aufruf sind sie aber weg! Hier ist das clientseitige Caching wohl kaputtgegangen. Aber auch dafür gibt einen Weg, und zwar muss man erzwingen, dass eine Anfrage wirklich immer an den Server rausgeht, dass der Browser das MHTML also niemals in Eigenregie cached. Der Server kann dann gerne ein kurzes „Alles wie gehabt, nimm was'de hast“ antworten und darauf verzichten alles neu zu senden. Aber die Anfrage muss raus.
Wem der IE Wurst ist, der ist sowieso fein raus. Oder man greift zur adaptiven Degradation in Sachen Ladezeiten und serviert den IEs die klassischen Bilder aus einem zweiten Stylesheet heraus. Je nach Gusto.
Dateien mit längeren Verfallsdaten ausstatten
Das hier ist eine sehr wirksame Geschichte: es geht darum, Dateien, die sich kaum verändern und die man einmal erfolgreich an den Mann gebracht hat, weiterhin dort vorrätig zu halten, so dass diese Daten bei einem erneuten Besuch dieser Person nicht nochmal angefordert werden, sondern die noch im Browser liegenden verwendet werden. Wir steuern also das Browser-Caching.
Zwar ist es sicherlich so, dass sich die JavaScript-Dateien und auch das CSS einer in der Entwicklung befindlichen, aber auch einer frisch gelaunchten Seite noch ändern - ist eine Seite aber eine Weile erfolgreich und ohne Wehwehchen am Laufen dann stehen die finalen Dateien fest.
Warum diese also unnötig neu laden? Deshalb können wir nun hingehen, und über einen der unterschiedlichen Wege, HTTP-Header zu setzen, definieren, dass beispielsweise .js, .css, sowie alle .gif. jpg. und .png Dateien einen vollen Monat lang gespeichert sein dürfen ohne neu geladen zu werden. Und das bedeutet wiederum, dass nach dem allerersten Aufruf einer Seite bei allen Folgeseiten nur noch das Inhaltsdokument von bestenfalls einigen Kilobytes und mit einem oder nur wenigen HTTP-Requests geladen wird.

Das spart nicht nur Ladezeit, sondern auch der Webserver hat ein laueres Leben und der Webseiten-Traffic sinkt obendrein noch. Unter Apache können wir das Browsercaching durch einen Eintrag in eine/die eine .htaccess-Datei in unserem Basisverzeichnis erzwingen:
<IfModule mod_expires.c>
ExpiresActive On
ExpiresDefault "access plus 1 minutes"
ExpiresByType text/html "access plus 1 minutes"
ExpiresByType text/css "access plus 1 months"
ExpiresByType text/javascript "access plus 1 months"
ExpiresByType text/plain "access plus 1 months"
ExpiresByType application/javascript "access plus 1 months"
ExpiresByType application/x-javascript "access plus 1 months"
ExpiresByType application/x-shockwave-flash "access plus 1 months"
ExpiresByType image/gif "access plus 1 years"
ExpiresByType image/jpeg "access plus 1 years"
ExpiresByType image/jpg "access plus 1 years"
ExpiresByType image/png "access plus 1 years"
ExpiresByType image/x-icon "access plus 1 years"
<FilesMatch ".*\.mhtml$">
ExpiresActive Off
</FilesMatch>
</IfModule>
Das ganze setzt ein aktiviertes Module "Expires" voraus, was es bei den meisten Hostern aber gibt. Ausprobieren. In diesem konkreten Fall verfallen CSS und JavaScript nach einem Monat, Bilder sogar erst nach einem Jahr. Erst dann schaut der Browser nach etwas Neuem. Und ich habe auch eine Ausnahme für .mhtml-Dateien drin, damit diese nicht gecached werden.
Wer übrigens gerne beides hätte, sprich: hohe Vorhaltezeiten im Browser solange die Dateien sich nicht ändern und garantiertes Neuladen beim Update von Dateien, der sollte mit Versions- oder Datums-Parametern hinter den verlinkten Dateien arbeiten:
<link rel="stylesheet" type="text/css" href="styles.css?v=1.0" />
Beim nächsten Update der Datei ändert man den Link auf:
<link rel="stylesheet" type="text/css" href="styles.css?v=1.1" />
Das zwingt den Browser dazu, die Datei neu zu laden. Wer das automatisiert haben mag und PHP verwendet, der kann mit so einem Verfahren arbeiten:
echo '<link rel="stylesheet" type="text/css" href="styles.css?timestamp='.filemtime('styles.css').'" />';
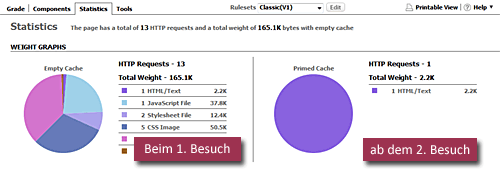
Die zweitbeste Methode ist diejenige, wo der Browser die Dateien nicht cached, er also alle Anfragen beim zweiten Seitenaufruf erneut stupide erzeugt, der Server aber seinerseits feststellt (anhand von sogenannten ETags), dass sich anscheinend nichts geändert hat und mit einem kurzen und knackigen „304 Not Modified“! antwortet. Das war's auch schon, die Latenz bleibt, aber die komplette Nutzlast fällt immerhin weg.
Peter hat das hier in seinem Blog auf diese Art eingerichtet, und so werden aus den 206.7KB des ersten Seitenaufrufs schlanke 7.7KB ab dem zweiten (es bleibt aber immer bei den vollen 47 HTTP-Requests, die bei der optimalen Methode auch noch wegfallen könnten).
Daten komprimiert verschicken
In Zeiten wo man die Quadcores hinterhergeworfen bekommt, warum nicht ein paar Rechenzyklen darauf verpulvern alle komprimierbaren Daten, das sind vor allem Textdateien, beim Versenden per ZIP-Verfahren kleinzuschrumpfen? Und das verstehen auch alle anständigen Browser.
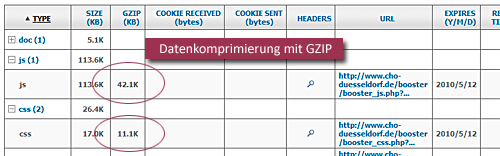
Ganz speziell hilft uns das bei großen JavaScript-Libraries, aber auch beim Eindampfen von Data URI Einbettungen, und wir aktivieren das wiederum mit einem Eintrag in einer/der .htaccess-Datei in unserem Basisverzeichnis:
<FilesMatch ".*\.(html|php|css|js)$"> SetOutputFilter DEFLATE </FilesMatch>
JavaScripts in den Quelltext-Fußbereich
Warum JavaScript nicht in den Kopfbereich des Quelltextes? Nun, das Problem mit JavaScript ist dass es vom Browser vollkommen anders angefasst wird als andere Dateitypen. Der Browser rechnet bei JavaScript-Dateien nämlich mit dem Schlimmsten (= document.write), und blockiert das progressive Weiterrendern der Seite so lange, bis die verlinkte JavaScript-Datei vollständig geladen und geparsed, und die Gefahr eines document.write gebannt ist. Wenn Sie nun einen riesen Brummer von JavaScript-Datei in den Kopf der Seite packen, dann geht halt erst einmal gar nichts für den User.
Packen Sie sie hingegen vor das schließende </body>, dann bekommt Ihr Besucher ihre komplette Seite schonmal zu Gesicht, und dass der Browser nun am Schluss festhängt, das fällt dem Benutzer sowieso nicht auf, weil er sich ersteinmal orientiert. Ein wirklich effektiver psychologischer Trick!
JavaScript minifizieren (CSS aber auch)
Über den Begriff „minifizieren“ sind bestimmt alle schon gestolpert, spätestens wenn es um das Einbinden von JavaScript-Bibliotheken ging: hier bieten die Hersteller immer auch „minified“ Versionen an. Worum geht es bei dieser Minifiziererei? Grob gesagt darum, mit genialen Kniffen so viel unnötige Zeichen aus der JavaScript-Programmierung rauszuwerfen wie nur möglich, ohne sie dabei zu zerstören. Dazu werden Umbrüche und Leerzeichen entfernt, aber auch Variablen und Funktionen umbenannt in so etwas Kurzes wie „a“ oder „b“. Das spart richtig viel Platz: jQuery schrumpft minifiziert von 155 KB auf 72 KB (was per ZIP beim Ausliefern nochmals auf 24 KB schrumpft). Wow!
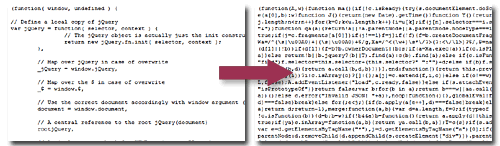
Bei CSS werden Anweisungen in sogenannten Shorthand Anweisungen zusammengefasst und HEX-Farbwerte in Kurzformen überführt. Das spart nicht so viel, aber hey, immerhin.
Die Tools der Wahl sind da der Yahoo! YUI Compressor, eine Java-Applikation, die sowohl JavaScript als auch CSS eindampfen kann, sowie der Google Closure Compiler, der ebenfalls in Java geschrieben ist, der aber nur JavaScript minifizieren kann. Als PHP-Libraries gibt dann noch JSMin+ und CSSTidy.
CSS-JS-Booster
So, und weil alles das echt saumäßig viel Stupido-Arbeit ist und eigentlich auf jeder Seite, egal wie groß, von Nutzen ist, bin ich eines schönen Tages im letzten Jahr hingegangen und habe das ganze in eine schöne PHP5 Library hineingesteckt und diese auf Github abgelegt. „Nomen est Omen“ und deshalb heißt das gute Ding auch CSS-JS-Booster, kurz der Booster.
Was nimmt der Booster Euch alles an Arbeitsschritten ab?
Der Booster arbeitet zweigleisig: einmal auf der CSS-, einmal auf der JS-Schiene. Manche Teilschritte sind dieselben, manche unterscheiden sich. Beide Teile können auch separat verwendet werden, zum Beispiel wenn man nur den JS-Teil gebrauchen kann.
CSS Optimierung
- Der Booster bekommt einen Haufen CSS-Sourcedateien übergeben (oder CSS im Klartext im „stringmode“), die er der Reihe nach in ein großes Workfile hineinzieht. Findet er @import-Regeln im CSS, dann werden auch die an der entsprechenden Stelle in das Workfile hineingezogen, und alle Dateipfade darin entsprechend angepasst.
- Im nächsten Schritt wird das CSS nochmal optimiert (minifiziert) mit Hilfe der Bibliothek „CSS Tidy“, die Einstellungen sind nicht extrem sondern möglichst ungefährlich und orientieren sich an einer Empfehlung von Dirk Jesse.
- Nun durchforstet der Booster das CSS nach Bildverweisen, und wenn er einen findet dann schaut er auf der Platte ob er die Datei dort finden kann. Ist dem so, und ist sie kleiner als 24KB, dann liest er diese Datei ein, und je nach Browser des Users kodiert er die Daten ins Base64-Format und bettet sie als Data URI ins CSS ein, oder aber, wenn es sich um einen älteren IE handelt, dann schreibt er eine MHTML-Datei raus und verweist im CSS auf diese.
- Beim Erzeugen des HTML-Codes zum Einbetten der CSS-Dateien, splittet er diese wieder auf in zwei gleichgroße Stylesheets, um die Tatsache auszunutzen dass die Browser mehrere Dateien parallel laden können und da tatsächlich schneller sind.
- CSS wie auch MHTML werden bei der Ausgabe GZIP-komprimiert
- Der Booster kümmert sich um ein effektives server- und clientseitiges Caching mit Timestamping. Wird das CSS aktualisiert, liefert er ein neues CSS aus. Aber nur dann.
- Der Booster umgeht den Bug des IE7 auf Vista mit den MHTML-Dateien
- Der Booster repariert das CSS-Hintergrundbild-Caching im IE6
- Der Booster GZIP-komprimiert auch die Seite, in die das CSS eingeklinkt wird
JavaScript Optimierung
- Der Booster bekommt einen Haufen JS-Sourcedateien übergeben (oder JavaScript im Klartext im „stringmode“), die er der Reihe nach in ein großes Workfile hineinzieht.
- Im nächsten Schritt wird das JS an den Google Closure Compiler Webservice verschickt und, sofern es nicht die maximale POST-Grenze des Google Closure Compilers von 200KB überschreitet, minifiziert zurück in Empfang genommen.
- Das JavaScript wird bei der Ausgabe GZIP-komprimiert
- Der Booster kümmert sich um ein effektives server- und clientseitiges Caching mit Timestamping. Wird das JavaScript aktualisiert, liefert er ein neues JavaScript aus. Aber nur dann.
Cache Optimierungen für alles andere via .htaccess
Desweiteren habe ich auch eine .htaccess-Datei beigefügt, die sinnvolle Caching-Einstellungen für Bilder auf dem Webspace vornimmt, und die man in das Basisverzeichnis des Webservers kopieren kann/darf/sollte.
Anwendung des CSS-JS-Boosters
Das Einbinden des Boosters ist eine ganz einfache Sache: Ladet die aktuelle Version bei Github herunter und hängt das entpackte Verzeichnis „booster“ irgendwo auf Eurer Webseite ein. Dann braucht es noch ein Unterverzeichnis darin namens „booster_cache“ mit Schreibrechten zum Cachen der serverseitig generierten optimierten Dateien. Dann binden wir die Bibliothek ein und erzeugen ein neues Booster-Objekt:
include('booster/booster_inc.php');
$booster = new Booster();
Dann sagen wir dem Booster welche CSS- und JS-Dateien wir verarbeitet haben wollen. Dazu nennen wir ihm entweder ein Verzeichnis, dessen Dateien er alphabetisch einliest…
$booster->css_source = 'css-folder'; $booster->js_source = 'js-folder';
oder eine Datei…
$booster->css_source = 'css-folder/styles.css'; $booster->js_source = 'js-folder/javascript.js';
oder mehrere Verzeichnisse und/oder Dateien per Array, gerne wild gemischt…
$booster->css_source = array('css-folder-a','css-folder-b','css-folder-b/styles.css');
$booster->js_source = array('js-folder/javascript-a.js',''js-folder/javascript-b.js');
Zu guter letzt platzieren wir ein
echo $booster->css_markup();
an die Stelle wo der Booster unser CSS-Link-Markup ausspucken soll, idealerweise irgendwo im Kopfbereich der Seite, und ein
echo $booster->js_markup();
an die Stelle, wo der Booster das JavaScript-Markup ausgeben soll, idealerweise vor dem schließenden Body-Tag.
Das war's auch schon, fertig! Seite sollte nun schnell sein. Wer nur einen Teil von beiden nutzen will, der kann den anderen auch weglassen.
Das Wordpress-Plugin
Damit auch der weniger nerdige Netizen in den Genuss einer Webseitenbeschleunigung kommt, aber auch weil es so viele Wordpress-Seiten gibt, weil das die Bibliothek populärer macht und nicht zuletzt weil ich Bock drauf hatte, habe ich ein entsprechendes WP-Plugin als Spinoff gebaut.
Ein, zwei Dinge handhabe ich hierbei anders: Zum einen schalte ich den Google Closure Compiler hier ab, da ich denke, dass es durchaus Plugins gibt, deren JavaScript so unsauber ist, dass sie einem kaputt gingen. Und wer wäre es dann Schuld? Ich natürlich! Zum anderen hänge ich mich erst kurz vor der endgültigen Ausgabe des gesamten HTML hinein, und schnappe mir das HTML. Dann durchforste ich es ausschließlich im Kopfbereich (Head-Element) nach CSS und JS Einbettungen und Inline-Code - nur im Head deshalb weil sonst die Gefahr groß ist dass etwas kaputt geht, das per document.write in den Body schreibt (z.B. Werbebanner). Die Pfade zu diesen Dateien löse ich auf, Inline-CSS oder -JS verfrachte ich in neuerzeugte lokale Dateien. Ebenso downloade ich externe Dateien in neue lokale Dateien. Anschließend ziehe ich alle Dateien in den passenden Reihenfolgenden zusammen, optimiere alles, kommentiere die alten Verlinkungen im HTML-Code aus und bette meine neuen Dateien statt der alten ein. Zum Schluss gebe ich das HTML-Resultat dann endlich aus.

Funktionieren tut das ganze mit recht ansehnlichen Ergebnissen.

Download und weiterführende Infos zum Booster
Die CSS-JS-Booster Bibliothek bekommt Ihr hier und steht unter GNU Lesser General Public License V3.
Eine Übersicht über die Art und Weise der Einbindung bekommt Ihr im Wiki. Am besten, man steigt mit der Seite zum Basic Usage ein, und arbeitet sich dann gegebenenfalls tiefer in die Materie im Bereich Advanced Usage.
Das Wordpress-Plugin gibt es mit dabei, oder offiziell bei wordpress.org im Plugin Directory bzw. per Plugin-Suche in Wordpress selbst.
Wichtig: Der Booster ist ein reines PHP5 Konstrukt. Zum einen verwende ich neue PHP5 Befehle, die einem das Leben erleichtern, zum anderen verwende ich einen objektorientierte Aufbau auf den PHP4 leider nicht klarkommt. Dass mir da keine Beschwerden kommen! Falls Euer Provider Euch PHP4 aufgesetzt hat, erkundigt Euch wie Ihr den Webspace auf PHP5 umschalten könnt. Das geht fast immer.
Wenn Ihr Lust habt, baut auf Basis des Boosters gerne weitere CMS-Plugins, oder forked mich. Wenn Ihr Bugs findet (und das lässt sich nie vermeiden), gebt im Issue-Tracker Bescheid (aber checkt bitte vorher ob Ihr auch wirklich PHP5 am Start habt!).
Über den Autor
 Christian Schaefer ist Jahrgang '78, hat seine Wurzeln bei Köln, lebt aber seit 2004 unbehelligt in Düsseldorf, und wird von jedermann außer den Eltern „Schepp“ genannt. Und das ist auch gut so. Es verschlug ihn 1998 ohne Studium direkt in eine 3D-Firma in Köln. Dort entwickelte er virtuelle Figuren für Messen und TV. Selbstständigmachung Anfang 2004 und Verlagerung des Fokus' auf die Webentwicklung. Sieht seine Schwerpunkte bei der Frontend-Entwicklung, hat aber auch kein Problem mit Backends und dem Architekten großer Sites in PHP und MySQL. Fertige CMSe nerven ihn. Frameworks sind OK. Nebenbei unterstützt er technisch den Kölner Multimediatreff, hat gerade ein Videotraining biblischen Ausmaßes in der Mache. Er twittert unter dem Account derSchepp und mag alles was sich um Essen dreht.
Christian Schaefer ist Jahrgang '78, hat seine Wurzeln bei Köln, lebt aber seit 2004 unbehelligt in Düsseldorf, und wird von jedermann außer den Eltern „Schepp“ genannt. Und das ist auch gut so. Es verschlug ihn 1998 ohne Studium direkt in eine 3D-Firma in Köln. Dort entwickelte er virtuelle Figuren für Messen und TV. Selbstständigmachung Anfang 2004 und Verlagerung des Fokus' auf die Webentwicklung. Sieht seine Schwerpunkte bei der Frontend-Entwicklung, hat aber auch kein Problem mit Backends und dem Architekten großer Sites in PHP und MySQL. Fertige CMSe nerven ihn. Frameworks sind OK. Nebenbei unterstützt er technisch den Kölner Multimediatreff, hat gerade ein Videotraining biblischen Ausmaßes in der Mache. Er twittert unter dem Account derSchepp und mag alles was sich um Essen dreht.