Im Herbst geht es rund! Neben den üblichen Münchner HTML5- und CSS3-Terminen habe ich versucht, auf jeder Konferenz derer ich habhaft werden konnte, einen Workshop zu Web Components unterzubringen. Falls eure Konferenz in der folgenden Liste fehlt durfte ich entweder den Termin noch nicht veröffentlichen oder sie fehlt wirklich. Schickt dann den Veranstalter zu mir, denn die Welt braucht mehr Web Components!
18. - 20. August in München: HTML5-Schulung bei der Open Source School. Mein bewährtes dreitägiges HTML5-Standardprogramm stattet die Teilnehmer im Druckbetankungsverfahren mit so gut wie allem aus, was man zu HTML5 wissen muss. Von semantischem Markup bis hin zu Canvas-Frameworks ist alles dabei. Einen großer Praxisanteil mit überschaubaren Arbeitsgruppen stehen auf dem Plan und ein Exemplar des HTML5-Buchs gibt es obendrein.
21. und 22. August in München: CSS3 bei der Open Source School. Mein bewährtes zweitägiges CSS3-Standardprogramm katapultiert die Teilnehmer in das CSS3-Zeitalter, in dem Webfonts, Animationen und Farbverläufe fließen. Geboten wird auch hier ein großer Praxisanteil, kleine Arbeitsgruppen und mindestens ein CSS3-E-Book gibt es als Bonus.
26. Oktober in München: WebTech Conference. Auf der Agenda steht mein bewährter Workshop neue Techniken für Responsive Design, der sich mit Element Queries, Flexbox und den neuen Webstandards für Responsive Images befasst.
Termine unpassend, Orte alle zu weit weg und Programme nicht genehm? Ich komme auch gerne mit einem maßgeschneiderten Talk oder Workshop vorbei – mich kann man mieten!
Ich habe mich die letzteZeit intensiv mit Web Components (via Polymer) und aktuellen Webstandards rund um Responsive Design befasst. Eigentlich, so denkt man zunächst, bräuchte es auch für Web Components neue Responsive-Design-Webstandards. Das heutige Arbeitspferd für Responsive Design sind Media Queries, die (neben vielen anderen Nachteilen) den Haken haben, sich nur auf die Maße der gesamten Webseite bzw. des gesamten Devices beziehen zu können. Der reinen Lehre nach sollte eine Komponente aber komplett unabhängig vom Rest der Webseite sein, d.h. selbst entscheiden wann sie sich für weniger oder mehr Platz umbaut. Das ist allerdings nicht ganz einfach – nicht zuletzt, weil das eigentlich überhaupt gar nicht geht. Und ich glaube auch nicht, dass man das haben will.
Was eine wirklich komplett unabhängige Komponente bräuchte, wären nicht herkömmliche Media Queries zur Abfrage der Gesamtbreite von Device oder Webseite, sondern etwas zur Abfrage von der Breite eines bestimmten Elements (d.h. von sich selbst). Ein solches Feature hieße dann Element Query und trägt in sich das kleine Problem, dass es nicht funktioniert. Tab Atkins legt die Gründe hier und hier dar. Es gibt eine Vielzahl an konzeptionellen Problemen zu überwinden und wenn Element Queries auch nicht völlig unmöglich sind, so sind sie doch selbst im besten Fall noch viele Jahre von der Einsatzreife entfernt. Nicht nur gibt es keine Browserunterstützung, es gibt noch nicht mal einen konkreten Plan wie ein solches Feature überhaupt aussehen könnte.
Dessen ungeachtet gibt esdiverseProllyfills, die mit dem Element-Query-Konzept experimentieren. Wirklich ausgereift scheint mir keins dieser Scripts zu sein und insbesondere in Web Components konnte ich keinen der Kandidaten überzeugend zum Funktionieren bewegen. Und während ich noch damit herumspielte kam mir der Gedanke, dass man vielleicht gar keine Element Queries in Web Components haben möchte.
Zum einen stellt sich die Frage, ob man eine Responsive-Funktionalität, die so ausgefeilt wie Media Queries ist, überhaupt in seiner Komponente braucht. Dinge wie die Schriftgröße werden ohnehin von der umgebenden Webseite auf die Komponente vererbt – schrumpft die Schriftgröße via Media Query auf der Seite, so schrumpft sie auch in der Komponente. Sind Layout-Maße mit schriftgrößen-relativen Einheiten festgelegt, reduzieren auch sie sich gleich mit. Und baut man das Komponenten-Layout mit Flexbox, so kann man zumindest einfache Layout-Umbauten (z.B. den Wechsel zwischen einem Zwei- und Einspalten-Design) nur über Mindestmaße und flex-wrap, also ganz ohne Media Queries abbilden. Außerdem könnte ein Webdesigner mit entsprechenden Pseudoklassen direkt ins Shadow DOM hineingreifen um vor Ort und Stelle punktuelle CSS-Änderungen anzubringen. Häufig könnte das allein schon reichen aber selbst wenn nicht, weiß ich nicht, ob man Komponenten mit jeweils eigenen Element Queries haben will.
Wenn Komponenten gemäß der reinen Lehre sich komplett selbst managen und sie auch selbst via Element Query entscheiden, wann sie sich responsive rearrangieren, geht dem Webdesigner ein großes Stück Kontrolle verloren. Wo die Breakpoints für das Design der Webseite sitzen, würden dann plötzlich die Entwickler der Komponenten entscheiden! Das entsprecht aber eigentlich auch der reinen Lehre – wo kommen wir denn hin, wenn angeblich komplett in sich gekapselte Komponenten über das Aussehen der gesamten Webseite entscheiden? Ohnehin: so lange es keine nativen Element Queries gibt, müsste jede Komponente seine eigene Responsive-Logik in JS mitschleppen. Jeder Teil der Webseite hätte dann sein eigenes kleines Gehirn (inklusive eigener Bugs) und sein eigenes kleines Design und alles sieht aus (und resized sich) wie Kraut und Rüben. Das
kann eigentlich nicht die Lösung sein.
Aktuell erscheint es mir am Sinnvollsten, dass (mit JavaScript) auf der Webseite eine zentrale Responsive-Steuerung eingerichtet wird. Die Komponenten haben mehrere Layouts an Bord, entscheiden aber nicht selbst, wann welches Aussehen verwendet wird. Das regelt die zentrale Steuerung per Attributvergabe an die Komponenten. So bleibt alles inklusive der Komponenten schön responsive, aber die Breakpoints werden zentral gesteuert. Das, kombiniert mit den schon erwähnten Responsive-Automatismen (Flexbox, Schriftgröße) könnte ein schönes gemeinsames Bild ergeben. Und nicht zuletzt funktioniert eine solche Konstruktion ohne Wenn und Aber in modernen Browsern.
Zur Umsetzung dieses Prinzips muss eine Komponente (gebaut mit Polymer oder anderweitig) nur ein entsprechendes layout-Attribut unterstützen und sein Aussehen in Abhängigkeit davon regeln. Das ist zumindest in Polymer-Elementen recht unkompliziert:
Das Element unterstützt ein layout-Attribut mit den drei Werten small, medium und large und passt sein Aussehen mit dem Element-eigenen CSS an. Das Setzen dieses Attributs übernimmt dann einfach die Webseite, die das Element einbindet:
<!doctype html>
<title>Responsive Komponente</title>
<meta charset="utf-8">
<script src="bower_components/platform/platform.js"></script>
<link rel="import" href="x-layouts.html">
<x-layouts class="responsiveComponent"></x-layouts>
<script>
var components = document.querySelectorAll('.responsiveComponent');
var isLarge = window.matchMedia('(min-width: 600px)');
var isMedium = window.matchMedia('(min-width: 400px)');
var isSmall = window.matchMedia('(max-width: 400px)');
function resize(){
var layout = (isLarge.matches) ? 'large' :
(isMedium.matches) ? 'medium' : 'small';
for(var i = 0; i < components.length; i++){
components[i].setAttribute('layout', layout);
}
}
window.addEventListener('resize', resize);
window.addEventListener('load', resize);
</script>
Und das war es schon! Wenn man einen Haufen selbstentwickelter Komponenten hat, die alle das layout-Attribut unterstützen, braucht man keine einzige Code-Zeile mehr als das. Das einzig etwas abgefahrenere Feature in dieser Konstruktion ist window.matchMedia(), was aber außer in alten IE überall funktioniert und für die IE gibt es bekanntlich einen Polyfill. Für umfassende Unterstützung ist also gesorgt.
Zusammengefasst vereint diese Art von responsiven Komponenten mehrere Vorteile: sie funktionieren (im Gegensatz zu Element Queries) in jedem modernen Browser, erlauben die Zentralisierung der Breakpoint-Steuerung (im Gegensatz zu autonom entscheidenden Komponenten) und sind, wenn die Grundfunktion einmal implementiert ist, sehr einfach zu benutzen – vor allem wenn man bedenkt, dass man Polymer-Elemente von anderen Elementen erben lassen kann. Der Haken an der Geschichte ist, dass natürlich nie alle Komponenten auf dieser Welt eine einheitliche layout-Attribut-Unterstützung haben werden, sondern dass man damit vornehmlich eigene Komponenten wird ausrüsten können. Aber wenn man bedenkt, dass sich heutzutage die meisten Komponenten überhaupt gar nicht um das Responsive-Thema kümmern, ist das eigentlich kein wirklicher Rückschritt.
Eine vergleichsweise neue Entwicklung im Reich von ECMAScript 6 ist die Einführung von nativen Promises. Nachdem es schon lange Promises in JavaScript-Libraries gab, werden die praktschen Async-Helferlein in ES6 zum Sprachfeature erhoben. Die gute Nachricht dabei: die neuen Standard-Promises verhalten sich genau wie die alten JS-Promises (und auch wirklich nur wie die guten) und sie sind auch schon in einigen aktuellen Browsern implementiert.
Warum Promises? Warum native Promises?
Promises sind Objekte, die asynchrone Operationen kapseln. Sie zwängen asynchrone Operationen in eine einheitliche API, können verarbeitet werden bevor die Operation abgeschlossen ist und es gibt zahlreiche Möglichkeiten Promises zu kombinieren oder in Sequenzen zu verwenden. Sie haben sich (in Browser-JavaScript) als die Alternative zu Callback-Gewurschtel herausgebildet und werden unter anderem von jQuery unterstützt:
// Herkömmlicher Callback
$.get('/answer', function(data){
console.log(data);
});
// Promise-Objekt
var ajaxPromise = $.get('/answer');
// Promise-Objekt mit Callbacks und Verkettung
ajaxPromise
.then(function promiseCallback(result){
return JSON.parse(result);
})
.then(function erfolgCallback(parsed){
window.alert(parsed.answer); // > 42
}, function fehlerCallback(err){
console.error(err);
});
Die Details zu Promises kann man an anderer Stelle in epischer Breite nachlesen. Die eigentlich interessante Frage ist, warum man überhaupt mit ECMAScript 6 native Promises einführen sollte, wenn es doch jQuery (und vieleandereLibraries für Promises) gibt. Mindestens vier gute Gründe lassen sich nennen:
Kompatibilität: Die meisten Promise-Libraries produzieren Promises, die weitgehend kompatibel zueinander sind, aber es gibt Ausnahmen. Besonders jQuery tut sich hier negativ hervor und fabriziert Promises, die sehr andere Eigenschaften haben als in den meisten anderen Libraries. Außerdem hat jede Library eine ganz eigene API für die Erstellung von Promises. Vereinheitlichung an beiden Fronten wäre wünschenswert.
Performance: Wenn der Browser nativ Promises spricht, braucht man keine Extra-Library hierfür mehr in die Seite zu laden.
Browser-APIs: Native Promises können vom Browser direkt durch die divseren HTML5-APIs erzeugt und konsumiert werden. Funktionen wie geolocation.getCurrentPosition() könnten Geolocation-Promises erzeugen und die ulta-asynchronen Funktionen der Indexed DB könnten mit Promises statt des üblichen Callback-Krawalls viel übersichtlicher werden.
Gute Webstandards-Praxis: Es ist im Reich der Webstandards üblich, etablierte Patterns in den Standard aufzunehmen und so Hacks durch native Features zu ersetzen. So gibt es heute <video> statt Flash-Filmchen, document.querySelectorAll() statt $() und eben native Promises anstelle von JavaScript-Promises.
Da Promises vom Prinzip her sehr einfache Konstruktionen sind, gibt es bereits nennenswerte Browserunterstützung für dieses ES6-Feature und für uns einen guten Grund, native Promises unter die Lupe zu nehmen.
Die Promise-API in ES6
Die API für die Erzeugung von ES6-Promises gleicht der API von rsvp.js:
var promise = new Promise(function(resolve, reject){
resolve(42);
});
promise.then(function erfolgCallback(x){
window.alert(x);
});
Die Promises verhalten sich wie jene aus den zu Promises/A+ kompatiblen JS-Libraries; sie sind garantiert asynchron, fangen in Then-Callbacks geworfene Fehler ein und haben generell keine der aus jQuery bekannten Merkwürdigkeiten:
function fail(){
throw new Error('Epic fail!');
}
var promise = new Promise(function(resolve, reject){
resolve(42); // Garantiert asynchron
});
promise
.then(fail) // Error wird sauber eingefangen und nicht geworfen
.then(function(){
window.alert('Epic win!');
}, function(err){
window.alert(err.toString());
});
window.alert('Test'); // Passiert garantiert VOR Promise-Auflösung
Neben dem altbekannten then(erfolgCb, fehlerCb) haben Promise-Objekte noch eine catch()-Methode, die das Definieren eines Fehler-Callbacks ohne Angabe eines Erfolgs-Callbacks erlaubt; catch(cb) ist syntaktischer Zucker für then(undefined, cb).
Der Promise-Constructor bietet außerdem noch die folgenden statischen Methoden:
Promise.all(list) nimmt als Parameter eine Liste von Promises an. Die Funktion gibt ein Promise zurück, das mit einem Array der Werte der augelösten Promises aufgelöst wird. Wird eins der Elemente in der Liste abgelehnt, wird das Promise mit dem entsprechenden Wert ebenfalls abgelehnt.
Promise.race(list) nimmt als Parameter eine Liste von Promises an. Die Funktion gibt ein Promise zurück, das mit den Wert des ersten aufgelösten bzw. abgelehnten Promise aufgelöst bzw. abgelehnt wird.
Promise.resolve(x) gibt ein Promise zurück, das umgehend mit x aufgelöst wird.
Promise.reject(x) gibt ein Promise zurück, das umgehend mit x abgelehnt wird.
Da ECMAScript 6 noch längst kein fertiger Standard ist, sind Änderungen an diesen APIs natürlich nicht auszuschließen. So lange sich die ES6-Promises wie A+-Promises verhalten wäre das aber kein großes Problem, denn dann helfen wieder die guten alten Promise-Libraries.
Eine Zukunft für Promise-Libraries
Q, RSVP und all die anderen Promise-Libraries sind mit der Einführung von nativen Promises keinesfalls reif für die Rente. Alles, was ES6 in Sachen Promises liefert, ist eine Implementierung des Features „Promise“ und ein recht kleines Set an Promise-Tools (Promise.all(), Promise.race()).
Alle nennenswerten Promise-JavaScript-Libraries sind hingegen schwerpunktmäßig Tool-Sammlungen und haben nur nebenher auch eine Promise-Implementierung an Bord. Zu den Features von Q zählt z.B.:
Promise-Inspektions-Methoden wie promise.isFulfilled() und promise.isRejected()
promise.spread(), das wie then() funktioniert, aber den Inhalt eines als Array übergebenen Parameters als Einzel-Parameter an den Callback übergibt
Die Möglichkeit, NodeJS-Callbacks und jQuery-„Promises“ bequem in richtige Promises zu verwandeln
Promise-Poweruser werden auf derartige Tools auch in Zukunft nicht verzichten wollen, womit die Promise-Libraries weiterhin eine Existenzberechtigung haben. Sie werden vielleicht schlanker, aber sie werden uns erhalten bleiben.
Browserunterstützung und Fazit
Obwohl Promises als ES6-Feature noch gar nicht so alt sind, gibt es bereits Unterstützung in einigen Browsern. Opera und Chrome (auch mobile) haben das Feature schon länger im Angebot, Firefox (auch mobile) kann seit Version 29 damit aufwarten. Internet Explorer, Safari und der Android-Browser unterstützen Promises erwartungsgemäß nicht. Dieser löchrige Support ist jedoch kein Problem. Selbst wenn jeder Browser schon Promises unterstützen würde, würde man, wie schon erwähnt, aufgrund der vielen Komfort-Funktionen kaum auf die diversen Promise-Libraries verzichten wollen. Da diese Libraries ihre eigenen Promise-Implementierungen mitbringen, ist jetzt wie auch in Zukunft für flächendeckende Unterstützung gesorgt.
Das eigentliche Feature der ES6-Promises ist die Möglichkeit, dass sie jetzt auch native Browser-APIs verwendet bzw. angeboten werden können. Insofern ist die Einführung von nativen Promises vor allem eine Infrastruktur-Maßnahme und vielleicht gar nicht so sehr ein Features für die JavaScript-Entwickler selbst.
Nach gar nicht mal so langem Sammeln von Leserfragen musste ich diesmal sehr lange schreiben um die teilweise ausgesprochen kniffligen Fragen zu beantworten. Aber es ist geschafft! Und falls ihr meint, dass ihr für den nächsten Teil dieser Serie noch schwierigere Fragen auf Lager habt, schreibt sie mir per E-Mail oder gebt die Frage per Twitter ab.
HTML5 File APIs
Kann man mit der HTML5 File API Verzeichnisse auf dem Client auslesen?
Die File API definiert nur Funktionen, die mit Datei-Objekten im Browser arbeiten, aber dort ist kein Mechanismus festgehalten, wie diese Dateien in den Browser gelangen. Aktuellen Standards zufolge gibt es hierfür folgende Möglichkeiten:
Input-Elemente mit type="file" (DOM-Eigenschaft files)
Scripts, die selbst mit dem Blob-Constructor Datei-Objekte erzeugen
Das Auslesen eines Verzeichnisses ist nicht dabei. Die File System API sollte etwas derartiges ermöglichen, ist allerdings aktuell nur in Browsern mit Blink-Engine (Chrome und Opera) zu finden und wird vom W3C auch nicht mehr als Standard weiterentwickelt. Für den Fall, dass man dringend in einer Webapp ein simuliertes Dateisystem braucht, wird allgemein empfohlen, ein solches auf Basis von Indexed DB (die Blobs speichern kann) selbst zu bauen.
hgroup-Element - tot oder lebendig?
Ich versuche gerade mir HTML5 und CSS3 anhand deines Videotrainings von 2011 beizubringen. Ich bin dabei auf das <hgroup>-Element gestoßen, das laut einigen Meldungen seit Mitte letzten Jahres nicht mehr gültig sein soll. Auch du bestätigst diese Aussage auf deiner Webseite im August 2013, obgleich das Element auch heute noch – also ca. ein Jahr später – in den Spezifikationen der WHATWG auftaucht. Meine Fragen:
Existiert <hgroup> nun endgültig nicht mehr oder ist sein Status weiterhin ungeklärt? Klar, kaum jemand benutzt es und deshalb kann von einer Nicht-Existenz gesprochen werden, aber ist es auch offiziell?
Im Netz geistern die Alternativen zu <hgroup> herum. Inwiefern sind diese aktuell, bzw. offiziell?
Wie gehst du in HTML mit auftauchenden Untertiteln, Zusatztiteln etc. um?
Das ist ausgesprochen kompliziert.
Die Frage an dieser Stelle ist, was bei semantischen Elementen „Existenz“ ausmacht. Wie du richtig sagtest steht <hgroup> weiterhin in den Spezifikationen der WHATWG, fehlt aber beim W3C. Die Browser unterstützen meinen Tests zufolge das Element auch insofern, als dass es zumindest oberflächlich betrachtet implementiert ist (document.createElement('hgroup').toString() !== '[object HTMLUnknownElement]'). Andererseits macht das Element nur im Kontext des Outline-Algorithmus richtig viel Sinn und dass dieser Algorithmus ein reiner Papiertiger ist, ist eigentlich Konsens. Wenn man das Element in eine Webseite einbaut, macht es nichts. Man könnte also sagen, dass das Element zwar da ist, aber eigentlich nicht wirklich zu etwas gut ist. Das <hgroup>-Element ist Stand Mitte 2014 der Blinddarm von HTML5.
Es gibt keinen in Stein gemeißelten 1:1-Ersatz. Die Spezifikationen von W3C und WHATWG haben je einen Abschnitt "Common idioms without dedicated elements" in dem es beim W3C auch Empfehlungen zu Untertiteln und derartigem abgibt. Das sind allerdings auch nur Vorschläge, denen man folgen kann, aber nicht muss.
Ich persönlich folge den W3C-Empfehlungen, gruppiere also Überschriften mit Untertiteln usw. in <header>-Elementen, wobei die Untertitel keine Überschriften-Elemente, sondern irgend etwas anderes sind. Ich mache das nicht, weil es das W3C so empfiehlt, sondern weil die dortigen Vorschläge meiner Meinung nach einfach eine sehr gute Lösung darstellen. Würde man <hgroup> verwenden, wäre das eine (recht riskante) Wette darauf, dass sich dieses Element im Laufe der Zeit doch noch durchsetzt. Im Vergleich zu z.B. einem <header>-Element gibt es bzgl. Lesbarkeit des Quelltextes, Barrierefreiheit oder Browserunterstützung keinen Vorteil für <hgroup>. Der einzige Unterschied liegt in der Behandlung der enthaltenen Überschriften unter den Bedingungen des Outline-Algorithmus, der, wie erwähnt, keine Rolle spielt. Alles in allem: man könnte <hgroup> zwar benutzen ohne größere Katastrophen auszulösen, aber man hat nichts davon und geht dafür das Risiko ein, in Zukunft ein ungültiges Dokument haben (ohne dass die dann bestehende Ungültigkeit irgendwelche negativen Folgen hätte, denn jeder Browser auf diesem Planeten würde es ohne zu klagen verarbeiten).
Zwei zusätzliche Anmerkungen möchte ich zu diese Fragen noch loswerden. Erstens: Webstandards sind keine Wissenschaft. Der Prozess, in dem neue Regeln entstehen, ist unübersichtlich und obwohl es im Prinzip Regeln für den Prozess gibt, ist das Dehnen dieser Regeln an der Tagesordnung. Wird dann irgendwann mal eine neue definitive Regel aufgeschrieben, ist immer noch nicht auszuschließen, dass kurze Zeit später wieder die Kehrtwende kommt. Oder es kann passieren, dass das, was aufgeschrieben irgendwo steht, aus guten Gründen ignoriert wird. Es ist in letzter Konsequenz Politik.
Zweitens: „Offiziell“ ist überbewertet. Eigentlich ist etwas „offiziell“ ist etwas, sobald ein Dokument ein fertiger Webstandard (Recommendation) ist. Das allein muss aber auf die gelebte Praxis nicht unbedingt Auswirkungen haben. So war z.B. CSS 2 lange Zeit Recommendation, wurde aber dann effektiv zurückgezogen, weil sich kein Browser an das hielt, was in dem Dokument stand. Ein wie auch immer gearteter „offizieller“ Status ist nicht so wichtig wie die Frage, ob ein Feature funktioniert und sinnvolle Dinge ermöglicht. Ich würde behaupten, dass <hgroup> nicht offiziell existiert (auch wenn auch nicht explizit abgeschafft ist), nicht funktioniert (es macht in Browsern schließlich nichts) und sinnvolle Dinge ermöglicht es auch nicht. Also weg damit!
Text messen ohne Browser
Wie kann man in Node.js herausfinden, welche Abmessungen ein Text bei einer bestimmten Schriftgröße mit einer bestimmten Schriftart hat? Wenn möglich ohne einen headless browser wie PhantomJS o.Ä. bemühen zu müssen …
Auch hier hilft, man glaubt es kaum, HTML5! Das Canvas-Element bietet eine Funktion, die genau das Gewünschte macht: measureText(x) nimmt einen Text x und schaut nach, welche Ausmaße er bei den aktuellen Schrift-Settings hat. Und natürlich gibt es eine Canvas-Implementierung für Node.js. Diese ist zwar wegen diverser Abhängigkeiten nicht ganz so einfach zu installieren wie die meisten anderen Node-Module, aber wenn das geschafft ist, kann man ganz normalen Canvas-Code zum Textvermessen schreiben …
var Canvas = require('canvas');
var canvas = new Canvas(200, 200);
var ctx = canvas.getContext('2d');
// Schrift-Einstellungen
ctx.font = 'bold 16px Georgia';
// Text ausmessen
var textMetrics = ctx.measureText('Wie breit wird das hier?');
console.log(textMetrics);
Kein PhantomJS, keine ungewöhnlichen APIs: es geht einfach!
CSS und Shadow DOM
Wie verhält es sich mit Styles und JavaScript im Zusammenspiel mit Shadow DOM? Muss davon ausgegangen werden, dass Styles und Scripts aus dem Haupt-Dokument in das Shadow DOM von Web Component überschwappen und dort dann recht umfangreiche Resets nötig werden?
Das ist eine nicht ganz einfach zu beantwortende Frage. Vor allem darf man nicht vergessen, dass Shadow DOM noch eine sehr experimentelle Technologie ist und Änderungen durchaus im Bereich des möglichen sind. Entsprechend vorsichtig sollten die folgenden Aussagen behandelt werden.
Grundsätzlich ist die Antwort auf die Frage ein ganz klares Jain. Einerseits liegt um einen Shadow-DOM-Baum eine Grenze. Diese Grenze kann nicht von Selektoren (CSS oder JavaScript) überschritten werden. Befindet sich im Eltern-Dokument eine Style-Regel für z.B. <h1>-Elemente, wird diese Regel nur die Elemente betreffen, die direkt im Dokument stehen – eventuell in Shadow DOM vorhandene <h1>-Elemente bekommen von dieser Regel nichts mit. Umgekehrt sind in einem Shadow Tree definierte Styles auch nur innerhalb dieses Shadow Trees gültig und beeinflussen das Dokument, in das der Tree eingebunden ist, nicht.
Andererseits unterliegen mit einem Shadow DOM ausgestattete Elemente den Regeln der ganz normalen CSS-Vererbung. Gibt es in einem Shadow Tree beispielsweise keine Festlegung auf eine Schriftfarbe, so wird die Schriftfarbe verwendet, die das Elternelement des Shadow Trees hat. Ein kombiniertes Beispiel für beide Fälle könnte so aussehen:
<!doctype html>
<meta charset="utf-8">
<title>Shadow DOM</title>
<style>
body {
color: red;
}
span {
font-weight: bold;
}
</style>
<p>Im nächsten Element steht <span>Shadow DOM</span></p>
<p>Wenn du das hier lesen kannst, kann dein Browser kein Shadow DOM</p>
<script>
var shadowHost = document.querySelectorAll('p').item(1);
var shadowRoot = shadowHost.createShadowRoot();
var content = '<style>span { letter-spacing: .5em; }</style>' +
'Hallo <span>Welt!</span>';
shadowRoot.innerHTML = content;
</script>
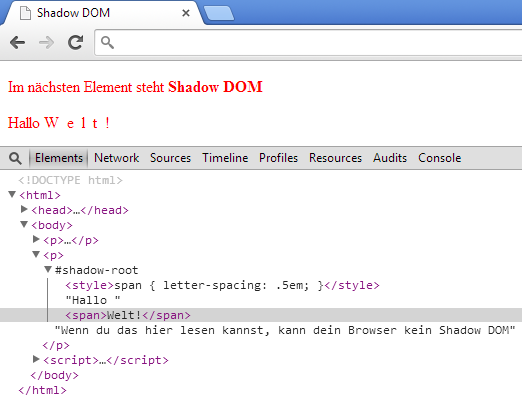
In einem Browser, der Shadow DOM korrekt umsetzt (z.B. Chrome 37) sollte das Ergebnis wie folgt aussehen:
Das Erscheinungsbild ergibt sich wie folgt:
Der Text ist überall rot, auch im Shadow DOM, da diese Regel vom <body>-Element weitervererbt wird und das Shadow DOM keine eigene Schriftfarbe festlegt
Nur <span>-Elemente außerhalb des Shadow DOM werden fett, da der Selektor nicht die Grenze zwischen Elterndokument und Shadow DOM überschreiten kann
Nur das <span>-Element im Shadow DOM ist von der letter-spacing-Deklaration betroffen, da auch hier der Selektor an der Grenze hängen bleibt
Fragt man mit JavaScript alle <span>-Elemente im Dokument ab, so wird nur ein einziges zurückgegeben – das Element außerhalb des Shadow DOM.
Zwischenzeitlich waren einige weitere Möglichkeiten geplant, um Einfluss auf die CSS-Balance zwischen Elterndokument und Shadow DOM zu nehmen. So sollte es einen Vererbungs-Reset für Shadow Trees geben, was in unserem Beispiel keine rote Farbe im Shadow DOM zur Folge hätte. Außerdem stand auch mal die Einführung eines Flags zur Diskussion, das CSS-Regeln aus dem Elternelement in das Shadow DOM durchgelassen hätte. Aktuell sind beide Features weder im neuesten Spezifikationsdraft noch in irgendwelchen Browsern zu finden.