
Viele Features in Service Workers wurden nicht extra neu spezifiziert, sondern sind Adaptionen existierender Standards. So ist z.B. Message Passing ein in jedem Browser schon vorhandenes Feature, das einfach auch in Service Workers zur Verfügung gestellt wird. Warum würde man das Rad auch neu erfinden, wenn man doch einfach vorhandene Funktionalität übernehmen kann! Allerhöchstens werden beim Vorliegen triftiger Gründe Teile eines Features nicht unterstützt. Das sehr praktische URL-Objekt ist im Service Worker verfügbar, wenn auch ohne die Methoden createObjectURL() und revokeObjectURL(), in denen die Spec-Schreiber nur schwer lösbare Garbage-Collection-Probleme für Service Worker sehen. Das ist auch recht gut nachvollziehbar. Eine Object-URL ist eine URL auf ein JavaScript-Objekt und damit, als theoretisch ewig gültige Referenz, schon in normalen Scripts nur schwer korrekt einzusetzen. Da sich das Problem im Kontext des Service-Worker-Lifecycle erheblich vergrößern würde, wird auf Object-URL-APIs einfach verzichtet. Schön und einfach für die Specs, aber, wie sich zeigen wird, nicht so schön und einfach für die Webapps!
Die Notification-API für per JS angestoßene native Notifications wurde ebenfalls in den Service Worker übernommen und funktioniert dort fast wie in normalen Websites auch. Wo man normalerweise einfach einen Constructor aufruft …
// In normalem JavaScript
const myNotification = new Notification("Master caution", {
body: "Main B bus undervolt!",
icon: "img/icon192.png",
});
… hat man im Service Worker eine Methode auf der aktuellen SW-Registration zur Verfügung …
// In Service-Worker-Code
self.registration.showNotification("Master caution", {
body: "Main B bus undervolt!",
icon: "img/icon192.png",
});
… aber das Grundprinzip ist identisch: einen Titel, einen Text und eine URL zu einem Icon angeben und schon taucht eine Notification auf! Allerdings gibt es beim Punkt „URL zu einem Icon“ ein handfestes Problem.
Service Worker haben viele Use Cases, aber der wichtigste ist sicher, Webapps offline zum Funktionieren zu bringen. Der Service Worker klemmt sich dazu als clientseitiger Proxy zwischen die Webapp und das WWW und ist in der Lage, von der App abgesetzte Requests auf die eine oder andere Weise zu beantworten.
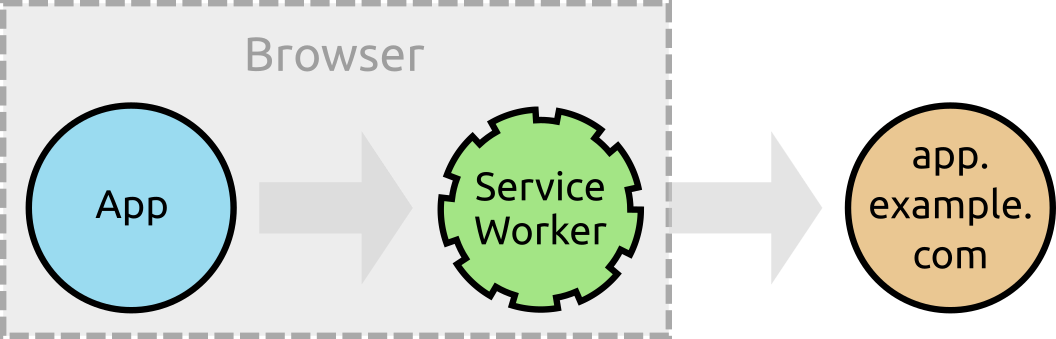
Für Offline-Support würde der Service Worker eingehende Requests aus seinem Offline-Cache beantworten. Wenn eine Ressource mal nicht im Cache ist oder sich ein Request nicht sinnvoll offline abbilden lässt, kann der Service Worker die Anfrage aber auch einfach aus dem WWW beantworten. Aus dem Cache kommt eine Ressource, wenn sie dort über die entsprechende JS-API herausgekramt wird. Aus dem WWW wird eine Ressource geladen, wenn der Request im Service Worker über eine der dafür üblichen APIs abgesetzt wird. Das wäre z.B. fetch() oder aber auch …
self.registration.showNotification("Master Caution", {
body: "Main B bus undervolt!",
icon: "img/icon192.png",
});
Houston, wir haben ein Problem! Die Notification-API nimmt für Icons nur URL-Strings entgegen. Diese URLs führen immer zu WWW-Requests, werden also auch im Offline-Betrieb garantiert nicht aus dem Cache bedient, selbst wenn die entsprechenden Icons dort lagern (denn Reqests aus dem Service Worker heraus führen immer ins Web, nie in den Cache). Eine URL auf eine aus dem Cache geladene Ressource lässt sich auch nicht so einfach basteln, da ja URL.createObjectURL() im Service Worker aus gutem Grund nicht verfügbar ist.
Alles verloren? Nicht ganz! Zwar ist URL.createObjectURL() nicht verfügbar, aber es gibt auch noch Data-URLs. Der Unterschied: während eine Object-URL ein Daten-Objekt referenziert, enthält eine Base64-codierte Data-URL die Daten selbst! Es gibt also keine Garbage-Collection-Komplikationen. Eine Data-URL auf einen Blob lässt sich mit der extrem archaischen FileReader-API erzeugen:
const reader = new FileReader();
reader.onloadend = () => { /* reader.result verwenden */ };
reader.readAsDataURL(blob);
Da die FileReader-API dem kreidezeitlichen XMLHttpRequest-Objekt ähnelt, lohnt es sich, sie hinter einem Promise zu verbergen. Die folgende Funktion nimmt eine URL entgegen und liefert, wenn es für die URL einen Cache-Eintrag gibt, ein Promise auf eine Data-URL mit dem Cache-Eintrag als Inhalt zurück. Gibt es keinen Cache-Eintrag für die URL, liefert das Promise die Input-URL zurück:
const asCacheUrl = (url) => {
return new Promise( async (resolve) => {
const response = await caches.match(url);
if (!response) {
return resolve(url);
}
const blob = await response.blob();
const reader = new FileReader();
reader.onloadend = () => resolve(reader.result);
reader.readAsDataURL(blob);
});
}
Eine hilfreiche Ergänzung ist die folgende Funktion, die für ein Array von URLs ein Promise auf ein Array von Data-URLs liefert:
const asCacheUrls = (urls) => Promise.all(urls.map( (url) => asCacheUrl(url) ));
Das Ganze in eine Notify-Funktion eingebaut und schon haben auch im Offline-Modus abgesetzte Notifications Icons und Bilder!
const notify = async (title, data = {}) => {
if (self.registration && self.Notification.permission === "granted") {
const [ icon, badge ] = await asCacheUrls([
"img/icon192.png", "img/badge.png"
]);
const options = Object.assign({ icon, badge, }, data);
const notification = self.registration.showNotification(title, options);
return notification;
}
}
Schon sieht es gar nicht mal mehr so schlimm aus!
Diese Funktion holt nur für die Felder icon und badge die Daten aus dem Cache. Um das Ganze für alle in Notifications verwendbaren Ressourcen durchzuführen, müsste ein Script sämtliche Felder des Optionen-Objekts von Notifications untersuchen und für die relevanten Einträge die Ressourcen aus dem Cache fischen. Ob es sich lohnt, eine ausgefeilte Library zum Lösen dieses Problemchens zu stricken, oder ob wir lieber warten sollten, bis sich die Spezifikationen darum kümmern, sei dahingestellt.